浪潮信息发布千亿级开源大模型“源2.0” 助力AIGC商业化进程
转自:中国科技网
科技日报记者 操秀英
11月27日,浪潮电子信息产业股份有限公司(简称浪潮信息)发布千亿级开源大模型“源2.0”。“源2.0”创新采用局部注意力过滤增强机制LFA (Localized Filtering-based Attention),可以有效捕捉局部信息和短依赖信息,使得模型能够更精准地掌握上下文之间的强语义关联,学习人类语言习惯范式本质,实现数理逻辑、数学计算、代码生成能力实现大幅提升。
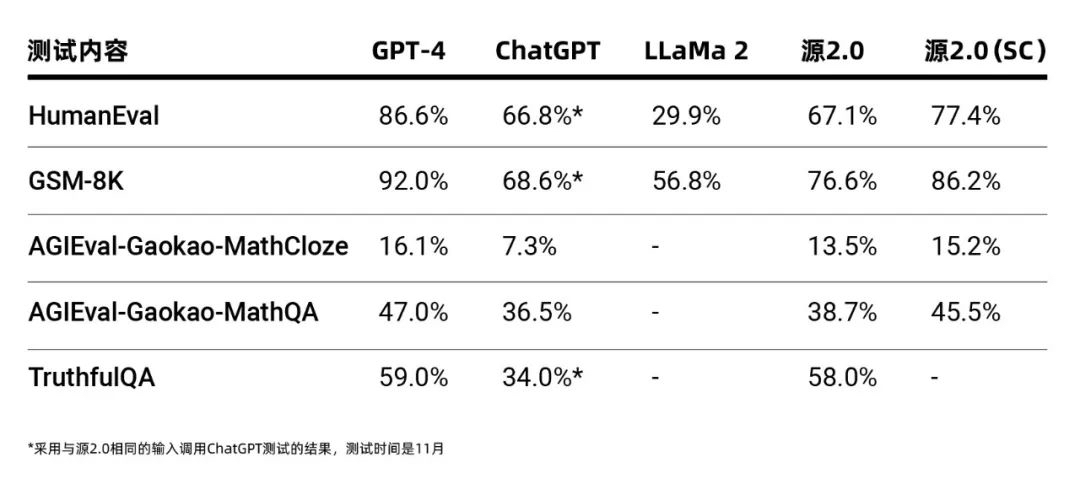
作为最早布局大模型的企业之一,浪潮信息于2021年9月在业界率先推出中文AI巨量模型“源1.0”,参数规模高达2457亿。浪潮信息人工智能软件研发总监吴韶华介绍道,“源2.0”在算法、数据、计算等方面都实现了极大创新。在算法上,“源2.0”首次提出具备有效捕捉局部信息和短依赖信息能力的LFA模型结构,使得模型能够更精准地学习人类语言范式本质。在数据处理方面,“源2.0”通过使用中英文书籍、百科、论文等资料,结合高效的数据清洗流程,可以更加高效地获取高质量数据集,提高训练效率。在计算方面,“源2.0”采用非均匀流水并行策略可有效缓解流水线头部与尾部的内存瓶颈,优化器参数并行则可以进一步降低流水线每个阶段的参数量。
更重要的是,浪潮信息宣布,“源2.0”实行全面开源,即模型全开源、免费可商用、无需申请授权。事实上,浪潮信息此前已推出“源1.0”开源开放计划,源开发者社区已汇聚了近万名高水平开发者,孵化出众多创新应用。
“Meta公司的LLaMA大模型开源之后,迅速吸引了大量开发者。”浪潮信息高级副总裁刘军表示,在国内,开源开放是促进AI技术发展和商业落地的重要手段,大模型的开源开放可以使不同的模型之间共享底层数据、算法和代码,有利于打破大模型孤岛,促进模型之间协作和更新迭代,并推动AI开发变得更加灵活和高效。
“只有把AIGC这块蛋糕做大,大家才能共享发展机遇,所以现在国内大模型厂商谈不上竞争,我们是合作关系。”刘军认为,开源开放有利于推进“技术+行业”的闭环,以更丰富的高质量行业数据反哺模型,打造更强的技术产品,加速商业化进程。
刘军透露,未来,依托浪潮信息在AI算力平台、OGAI智算软件栈等方面的长期技术积累,“源2.0”将持续为大模型创业者和开发者提供更加丰富、全面的助力和更加开放的技术创新空间。
(浪潮信息供图)