【信达电子】AI产业川流汇聚,云端两旺机遇开启
(来源:信达证券研究)
摘要

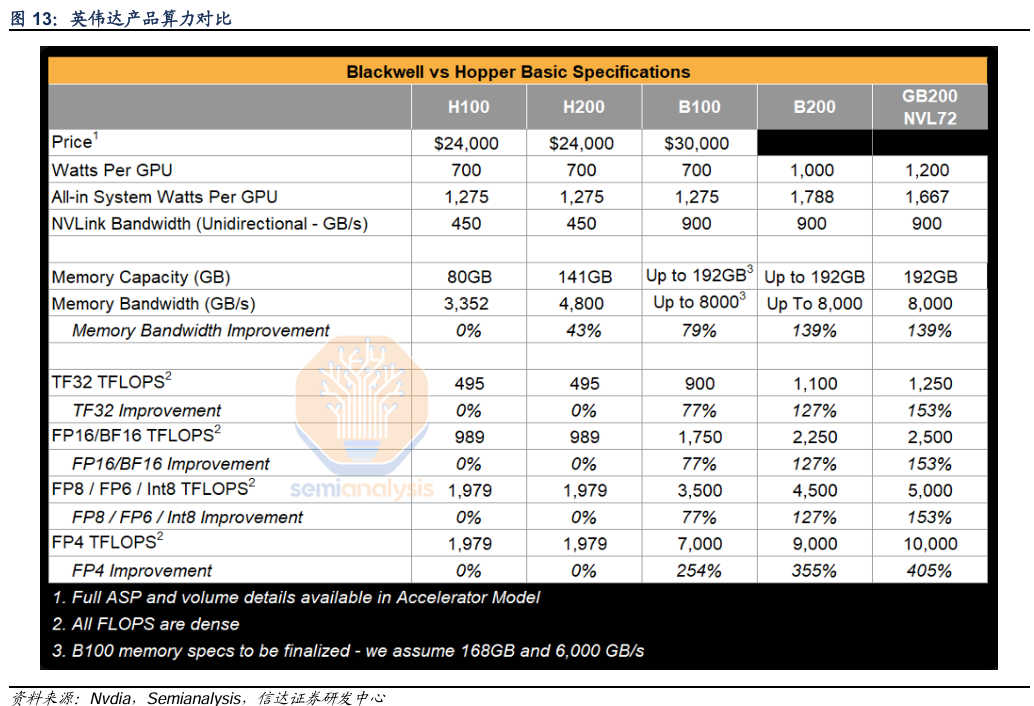
Blackwell众多技术突破,整体以机柜形式交货。GB200机柜有NVL36和NVL72两种规格。GB200 NVL36 配置中,一个机架有 36 个 GPU 和 9 个双 GB200 计算节点(以托盘为单位)。GB200 NVL72 在一个机架中配置了 72 个 GPU / 18 个双 GB200 计算节点,或在两个机架中配置了 72 个 GPU,每个机架上配置了 18 个单 GB200 计算节点。每个GPU 具有 2080 亿个晶体管,采用专门定制的台积电 4NP 工艺制造。所有 Blackwell 产品均采用双倍光刻极限尺寸的裸片,通过 10 TB/s 的片间互联技术连接成一块统一的 GPU。此外,B系列还有众多突破,支持 4 位浮点 (FP4) AI。内存可以支持的新一代模型的性能和大小翻倍,同时保持高精度。互联方面,第五代NVLink技术实现高速互联。NVIDIA NVLink 交换机芯片能以惊人的 1.8TB/s 互连速度为多服务器集群提供支持。采用 NVLink 的多服务器集群可以在计算量增加的情况下同步扩展 GPU 通信,因此 NVL72 可支持的 GPU 吞吐量是单个 8 卡 GPU 系统的 9 倍。此外,Blackwell 架构在安全AI、解压缩引擎、可靠性等方面也实现了不同程度的创新和突破。
Blackwell或成推理市场的钥匙,FP4精度潜力较大。目前模型参数变大的速度放缓,但模型推理和训练的运算量仍高速增长,尤其在o1引入强化学习之后,post scaling law开始发力。英伟达在发布H100架构时,便就FP8数据精度做出一定讨论。业界曾长期依赖 FP16 与 FP32 训练,但这种高精度的运算,在大模型LLM中受到了一定阻碍:由于模型参数等因素导致运算骤升,可能导致数据溢出。英伟达提出的FP8数据精度因为占用更少的比特,能提供更多运算量。以NVIDIA H100 Tensor Core GPU为例,相较 FP16 和 BF16,FP8 的峰值性能能够实现接近翻倍。FP4精度是FP8的继承和发展,对推理市场的打开有重要推动。GB200推出了FP4,FP4支持由于降低了数据精度,性价比相比H100几乎倍增。根据Semianalysis的数据,GB200 NVL72在FP4精度下,FLOPS相比H100可以最高提高405%(注:H100最低以FP8计算),由此带来性价比提升。目前,FP4的运算已经可以在大模型运算中广泛应用,且已有研究表明网络可以使用 FP4 精度进行训练而不会有显著的精度损失。此外,由于模型推理中不需要对模型参数进行更新,相对训练对于精度的敏感性有所下降,因此B系列相对于训练,在推理领域会更有优势。B系列引入FP4精度后,大模型在云侧和端侧的协同都有望实现跃升,这也是我们看好接下来的端侧市场的原因之一。
AI产业川流汇聚,2025年有望云端两旺。我们认为, B系列的推出有望打开推理市场,各类AI终端有望掀起持续的机遇。此外,AI产业的闭环有望刺激云厂商资本开支,云端共振共同发展。建议关注英伟达产业链传统的核心厂商,如ODM、PCB厂商等。此外,B系列带来的新兴赛道如铜连接、AEC赛道也值得关注。
风险因素:宏观经济下行风险;下游需求不及预期风险;中美贸易摩擦加剧风险。
报告正文
01
AI产业川流汇聚,云端两旺机遇开启
1.1
Blackwell众多技术突破,整体以机柜形式交货
GB200机柜有NVL36和NVL72两种规格。GB200 NVL36 配置中,一个机架有 36 个 GPU 和 9 个双 GB200 计算节点(以托盘为单位)。GB200 NVL72 在一个机架中配置了 72 个 GPU / 18 个双 GB200 计算节点,或在两个机架中配置了 72 个 GPU,每个机架上配置了 18 个单 GB200 计算节点。

计算托盘:每一个计算托盘有两个 NVIDIA GB200 Grace Blackwell 超级芯片。每个超级芯片将两个高性能 NVIDIA Blackwell Tensor Core GPU 和 NVIDIA Grace CPU 与 NVLink 芯片到芯片 (C2C) 接口连接起来,可提供 900 GB/s 的双向带宽。借助 NVLink-C2C,应用程序可以一致地访问统一的内存空间。这简化了编程,并支持万亿参数 LLM、用于多模态任务的 transformer 模型、用于大规模仿真的模型以及用于 3D 数据的生成模型的更大内存需求。
交换托盘:NVIDIA GB200 NVL72 引入了第五代 NVLink,它可以在单个 NVLink 域中连接多达 576 个 GPU,总带宽超过 1 PB/s,快速内存为 240 TB。每个 NVLink 交换机托盘提供 144 个 100 GB 的 NVLink 端口,因此这 9 台交换机完全连接了 72 个 Blackwell GPU 上每个 GPU 上的 18 个 NVLink 端口中的每一个。每个 GPU 的革命性 1.8 TB/s 双向吞吐量是 PCIe Gen5 带宽的 14 倍以上,为当今最复杂的大型模型提供无缝高速通信。

Blackwell 架构实现了较多的技术突破:
GPU工艺难度和晶体管数量上升。每个GPU 具有 2080 亿个晶体管,采用专门定制的台积电 4NP 工艺制造。所有 Blackwell 产品均采用双倍光刻极限尺寸的裸片,通过 10 TB/s 的片间互联技术连接成一块统一的 GPU。
第二代 Transformer 引擎及针对推理推出FP4数据精度。第二代 Transformer 引擎将定制的 Blackwell Tensor Core 技术与 NVIDIA TensorRT -LLM 和 NeMo 框架创新相结合,加速大语言模型 (LLM) 和专家混合模型 (MoE) 的推理和训练。为了强效助力 MoE 模型的推理 Blackwell Tensor Core 增加了新的精度 (包括新的社区定义的微缩放格式),可提供较高的准确性并轻松替换更大的精度。Blackwell Transformer 引擎利用称为微张量缩放的细粒度缩放技术,优化性能和准确性,支持 4 位浮点 (FP4) AI。这将内存可以支持的新一代模型的性能和大小翻倍,同时保持高精度。
第五代NVLink技术实现高速互联。第五代 NVIDIA NVLink 可扩展至 576 个 GPU,为万亿和数万亿参数 AI 模型释放加速性能。NVIDIA NVLink 交换机芯片可在一个有 72 个 GPU 的 NVLink 域 (NVL72) 中实现 130TB/s 的 GPU 带宽,并通过 NVIDIA SHARP 技术对 FP8 的支持实现 4 倍于原来的带宽效率。NVIDIA NVLink 交换机芯片能以惊人的 1.8TB/s 互连速度为多服务器集群提供支持。采用 NVLink 的多服务器集群可以在计算量增加的情况下同步扩展 GPU 通信,因此 NVL72 可支持的 GPU 吞吐量是单个 8 卡 GPU 系统的 9 倍。
此外,Blackwell 架构在安全AI、解压缩引擎、可靠性等方面也实现了不同程度的创新和突破。

1.2
Blackwell或成推理市场的钥匙,FP4精度潜力较大
目前模型的参数变大的速度放缓,但模型推理和训练的运算量仍高速增长。由于高质量训练语料的限制,目前模型参数变大的速度正在放缓。但是,模型训练和推理的运算量却在上升,尤其在o1引入强化学习之后,post-scaling law开始发力。
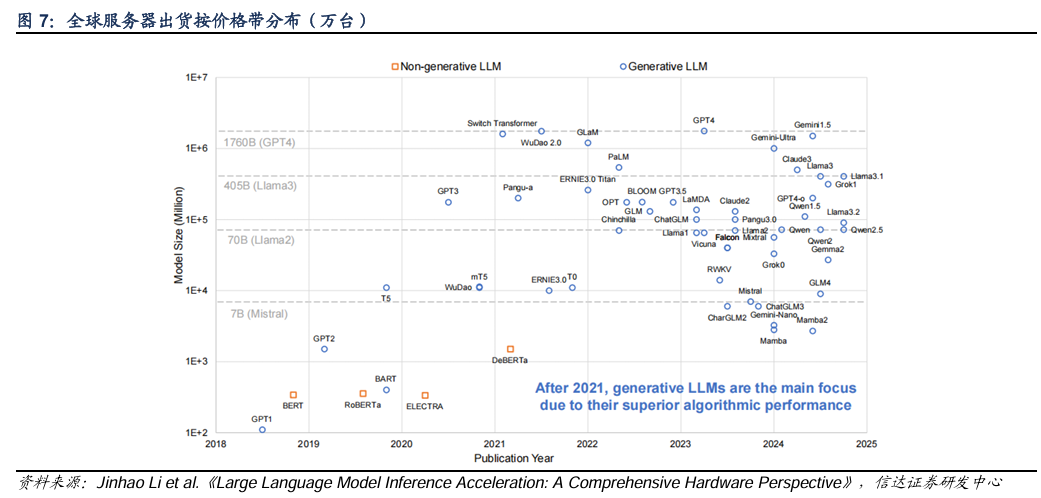
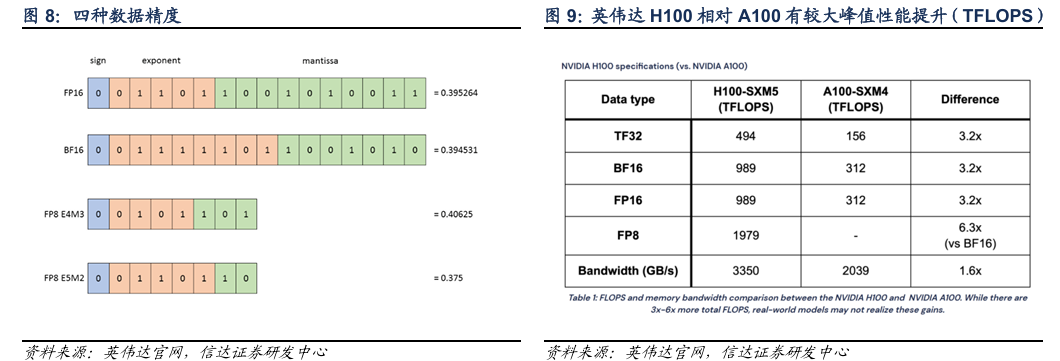
英伟达在发布Hopper架构时,便就FP8数据精度做出一定讨论。业界曾长期依赖 FP16 与 FP32 训练,但这种高精度的运算,在大模型LLM中受到了一定阻碍:由于模型参数等因素导致运算骤升,可能导致数据溢出。英伟达提出的FP8数据精度因为占用更少的比特,能提供更多运算量。以NVIDIA H100 Tensor Core GPU 上为例,相较 FP16 和 BF16,FP8 的峰值性能能够实现接近翻倍。
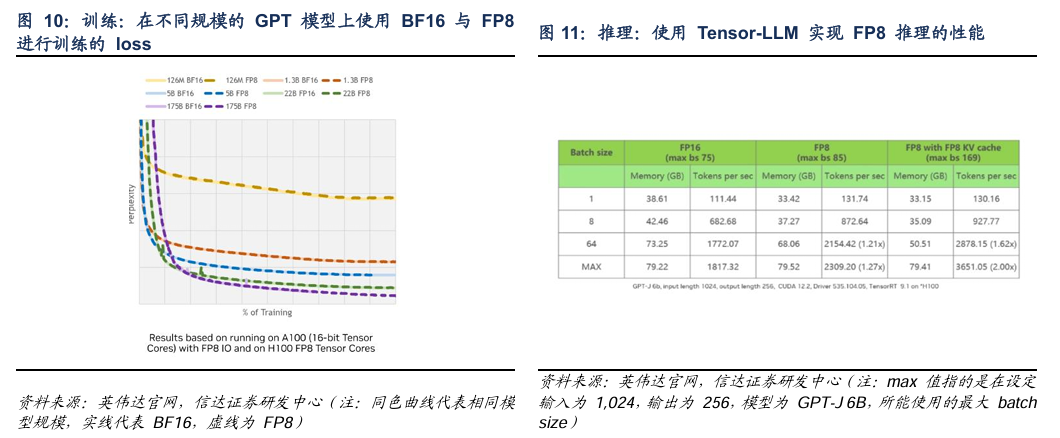
训练方面:在不同规模的 GPT 模型上使用 BF16 与 FP8 进行训练的 loss (损失值)曲线上,以困惑度 PPL(Perplexity) 为度量指标。观察 PPL 曲线走势,可见随着训练进程,FP8 与 BF16 的曲线几乎完全吻合,表明两者收敛性并无显著差异。
推理方面:单纯启用 FP8 会由于 batch size 提升有限,以及 KV cache 的影响,导致性能提升并不显著。然而,一旦将 KV cache 也转换至 FP8,通过减半其内存消耗,模型吞吐量可以相较 FP16 提升约两倍左右,这是一个理想的性能提升幅度。此外,从英伟达官方展示的资料来看,在运算量越大的任务中,FP8的性能提升幅度越接近上限。
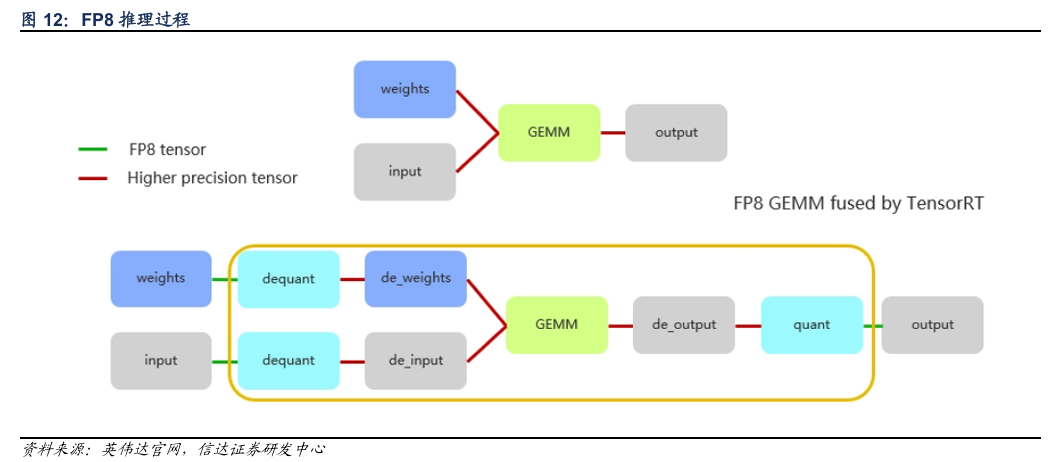
英伟达用FP8进行低精度训练取得较好的性能,模型量化是其中的重要手段。模型量化是一种深度学习的优化技术,目前已经取得了较为可观的进展。模型量化可以将神经网络中原本高精度数据运算转换至低精度,这样的优点主要有:(1)减少内存带宽和存储空间;(2)提高系统吞吐量;(3)降低系统延时等等。
FP4精度是FP8的继承和发展,对推理市场的打开有重要推动。GB200推出了FP4,FP4支持由于降低了数据精度,性价比相比H100几乎倍增。根据Semianalysis的数据,GB200 NVL72在FP4精度下,FLOPS相比H100可以提高405%(注:H100最低以FP8计算),由此带来性价比提升。
单位美元运算量:目前B的价格仍为公布,但是即便假设GB200 NVL72中的单张GPU价格为3.5万美元,单位美元可提供的算力相对H100仍是倍增。
存储:FP8精度下的运算对于内存的耗用相对较小,因此可以节省存储。或者说单位存储可以提供的运算能力倍增。
功耗:GB200单张GPU的功耗相对H100提升71%,算力提升405%,如此测算单位算力所耗费的能量大幅减少。
目前,FP4的运算已经可以大模型运算中广泛应用,且已有研究表明网络可以使用 FP4 精度进行训练而不会有显著的精度损失。此外,由于模型推理中不需要对模型参数进行更新,相对训练对于精度的敏感性有所下降,因此B系列相对于训练,在推理领域会更有优势。此外,B系列引入FP4精度后,大模型在云侧和端侧的协同都有望实现跃升,这也是我们看好接下来的端侧市场的原因之一。

AI产业川流汇聚,2025年有望云端两旺。我们认为, B系列的推出有望打开推理市场,各类AI终端有望掀起持续的机遇。此外,AI产业的闭环有望刺激云厂商资本开支,云端共振共同发展。建议关注英伟达产业链传统的核心厂商,如ODM、PCB厂商等。此外,B系列带来的新兴赛道如铜连接、AEC赛道也值得关注。
02
风险因素
电子行业发展不及预期;
宏观经济波动风险;
地缘政治风险。
研究团队简介
莫文宇,电子行业分析师,S1500522090001。毕业于美国佛罗里达大学,电子工程硕士,2012-2022年就职于长江证券研究所,2022年入职信达证券研发中心,任副所长、电子行业首席分析师。
郭一江,电子行业研究员。本科兰州大学,研究生就读于北京大学化学专业。2020年8月入职华创证券电子组,后于2022年11月加入信达证券电子组,研究方向为光学、消费电子、汽车电子等。
王义夫,电子行业研究员。西南财经大学金融学士,复旦大学金融硕士,2023年加入信达证券电子组,研究方向为存储芯片、模拟芯片等。
李星全,电子行业研究员。哈尔滨工业大学学士,北京大学硕士。2023年加入信达证券电子组,研究方向为服务器、PCB、消费电子等。